HTML
Robots.txt File vs Robots Meta Tag vs X-Robots-Tag
What are Robots.txt File, Robots meta tag, and X-Robots-Tag? How They are used to control or communicate what search engine spiders do on your website or web application.

What are Robots.txt File, Robots meta tag, and X-Robots-Tag? How These are used to control or communicate what search engine spiders do on your website or web application.
Table of Contents
1. What is Robots.txt File?
Robots.txt is a standard text file is used for websites or web applications to communicate with web crawlers (bots). It is used for web indexing or spidering. It will help the website that ranks as highly as possible by the search engines.
The robots.txt file is an integral part of the Robots Exclusion Protocol (REP) or Robots Exclusion Standard, a robots exclusion standards that regulate how robots will crawl the web pages, index, and serve that web content up to users.
Robots.txt file is used to allow and disallow the folder, files, and pages of the entire website.

2. Basic robots.txt examples
Here are some regular robots.txt Configuration explained in detail below.
Allow full access
[php]
User-agent: *
Disallow:
OR
User-agent: *
Allow: /
[/php]
Block all access
[php]
User-agent: *
Disallow: /
[/php]
Block one folder
[php]
User-agent: *
Disallow: /folder-name/
[/php]
Block one file or page
[php]
User-agent: *
Disallow: /page-name.html/
[/php]
3. Robots Meta Tag
Robots Meta Tag is used to Indexation-controlling the web page. It is a piece of code that is in the
tag of the HTML document. Meta robots tag tells what pages you want to hide (noindex) and what pages you want them to index from search engine crawlers. Meta robots tag tells search engines what to follow and what not to follow the content of the web pages or website.If you don’t have a Robots Meta Tag on your site, don’t panic. By default is “INDEX, FOLLOW”, the search engine crawlers will index your site and will follow links.
The Robots Meta Tag can be classified into Indexation-controlling parameters for the search engine crawlers:

follow
A command for the search engine crawlers to follow the links on that webpage or website.
index
A command for the search engine crawlers to index that webpage or website.
nofollow
A command for the search engine crawlers NOT to follow the links on that webpage or website. (Don’t confuse this NOFOLLOW with the rel=”nofollow” link attribute. It tells search engines to nofollow the content of the web pages or website.
noindex
A command for the search engine crawlers NOT to index that webpage or website.
noimageindex
A command for the search engine crawlers Tells not to index any images on a web page or website.
none
A command for the search engine crawlers Tells Equivalent to using both the noindex and nofollow tags simultaneously.
all
A command for the search engine crawlers Tells Equivalent to using both the index and follow tags simultaneously.
noarchive
A command for the search engine crawlers should not show a cached link to this page on a search result (SERP).
Nocache
A command is the same as noarchive but only used by Internet Explorer and Firefox browsers or User-Agents.
Nosnippet
A command for the search engine crawlers Tells not to show a snippet of this page (i.e., meta description) of this page on a search result (SERP).
notranslate
– A command for the search engine crawlers Prevents from showing translations of the page in their search results (SERP).
Noodyp/noydir
A command Prevents search engines from using a pages DMOZ description as the SERP snippet for this page. However, DMOZ was retired in early 2017, making this tag obsolete.
noyaca
– A command for the search engine crawlers Prevents the search results snippet by using the page description from the Yandex Directory. (Note: Only supported by Yandex.)
Unavailable_after
A command for the search engine crawlers should no longer index this page after a particular date.
An example of a meta robots tag code should look similarly:
[php]
<meta name ="robots" content="index,follow" />
<meta name ="robots" content="index,nofollow" />
<meta name ="robots" content="noindex,follow" />
<meta name ="robots" content="noindex,nofollow" />
[/php]
If you targeted to the specific search engine crawler for example, similarly
[php]<meta name="googlebot" content="noindex" />[/php]
If you need to specify multiple crawlers individually, it’s okay to use multiple robots meta tags similarly:
[php]
<meta name="googlebot" content="noindex">
<meta name="googlebot-news" content="nosnippet">
[/php]
Meta robots tag on web page example is as shown below
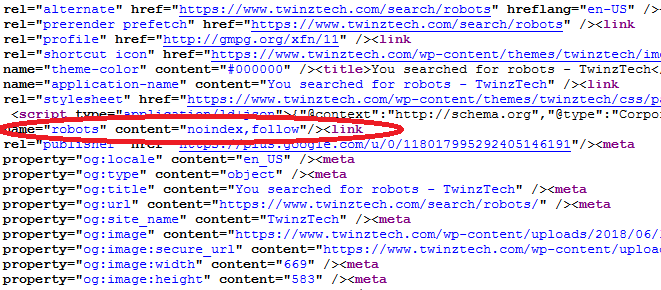
4. “unavailable_after” tag
REP has introduced a new META tag that allows you to tell us when a page should be removed from the main Google web search results: The likely named called unavailable_after tag.
For example, to specify that an HTML page should be removed from the search results after 6 pm Eastern Standard Time EST on 31st August 2018, add the following tag to the head section of the page.
[php]<meta name="googlebot" content="unavailable_after: 31-Aug-2018 18:00:00 EST">[/php]
The date and time is specified in the RFC 850 format.
This meta tag info is treated as a removal request. It will disappear from the search results a day after the removal date passes. The tag “unavailable_after” only support for Google web search results page.
After the removal, the page stops showing in Google search results, but it is not removed from your website. If you need to remove URL or content from google index, you can read Requesting removal of content from google index on Webmaster Central blog.
The Robots Meta Tags are used to control only the webpage (HTML) documents on your website. But it can’t control access to other types of materials, such as Adobe PDF files, video and audio files, and other models, etc. With the help of X-Robots-Tag, we can rectify this problem.
5. X-Robots-Tag HTTP header
X-Robots-Tag HTTP header is a simple alternative for Robots.txt and Robots Meta Tag. It is used to control more data then Robots.txt file and Robots Meta Tag.
The X-Robots-Tag is a part of the HTTP header to control indexing of a web page or website. It can be used as an element of the HTTP header response for a given URL of the web page.
By the Robots Meta Tag is not possible to control the other files such as Adobe PDF files, Flash, Image, video and audio files, and different types?. With the help of X-Robots-Tag, we can easily control the other data.
In PHP header() function is used to send a raw HTTP header. This would prevent search engines from showing files and following the links on those pages you’ve generated with PHP, you could add the following in the head of the header.php file:
[php]header("X-Robots-Tag: noindex, nofollow", true);[/php]
By the help of Apache or Nginx server configuration files or a .htaccess file.
A website which also has some .pdf and .doc files, but you don’t want search engines to index that filetype for some reason.
On Apache servers, you should add the following lines to the Apache server configuration file or a .htaccess file.
[php]
<FilesMatch ".(doc|pdf)$">
Header set X-Robots-Tag "noindex, noarchive, nosnippet"
</FilesMatch>
[/php]
On Nginx server, you should add the following lines to the Nginx server configuration file.
[php]
location ~* \.(doc|pdf)$ {
add_header X-Robots-Tag "noindex, noarchive, nosnippet";
}
[/php]
In such a case, the robots.txt file itself might show up in search results. By adding the following lines to the server configuration file, you can prevent this from happening to your website:
On Apache servers, you should add the following lines to the Apache server configuration file or a .htaccess file.
[php]
<FilesMatch "robots.txt">
Header set X-Robots-Tag "noindex"
</FilesMatch>
[/php]
On Nginx server, you should add the following lines to the Nginx server configuration file.
[php]
location = robots.txt {
add_header X-Robots-Tag "noindex";
}
[/php]
Helpful Resources:
1. How to Flush The Rewrite Rules or URL’s or permalinks in WordPress Dashboard?
2. 16 Best Free SEO WordPress plugins for your Blogs & websites
3. What is an SEO Friendly URLs and Best Permalink Structure for WordPress?
4. 16 Most Important On-Page SEO Factors To Boost Your Ranking Faster in Google
5. 16 Best (free) AMP – (Accelerated Mobile Pages) WordPress Plugins

Top Branding Tips to Strengthen Your Business Presence

Navigating the Future of Remote Work

13377x Original Site: 1337x Official Site, Proxy Sites, Movies, Torrents

LimeTorrents Alternatives: Proxy Sites to Unblock LimeTorrents.cc

Afdah Movies Alternatives – Watch Free HD Movies, TV Shows, Web Series
Einthusan Alternatives & Competitors – Streaming Movies, and Live TV Shows

Best practices for ethical user activity monitoring

How to Find a Great Paid Social Agency: Watch Out for These Pitfalls

How to Learn New Technologies and Tools More Easily

The Future of Tourism: Harnessing the Power of Technology
Buy IG likes and buy organic Instagram followers: where to buy them and how?

100% Genuine Instagram Followers & Likes with Guaranteed Tool

7 Must Have Digital Marketing Tools For Your Small Businesses
Instagram Followers And Likes – Online Social Media Platform

Use of 3D Printing in Injection Molding
Top 25 Best SolarMovie Alternatives Updated List
13377x Original Site: 1337x Official Site, Proxy Sites, Movies, Torrents

Principles of Good Software Engineering

How To Get Started With Artificial Intelligence

Tamilrockers Alternatives: TamilRockers Proxy and Mirror Sites [working]
-
Instagram4 years ago
Buy IG likes and buy organic Instagram followers: where to buy them and how?
-
Instagram4 years ago
100% Genuine Instagram Followers & Likes with Guaranteed Tool
-
Business5 years ago
7 Must Have Digital Marketing Tools For Your Small Businesses
-
Instagram4 years ago
Instagram Followers And Likes – Online Social Media Platform